 English
English 

Automatic Acquisition of High-fidelity Facial Performances Using Monocular Videos
We present a video-based motion capture technique that automatically and accurately captures high-fidelity facial performances using uncontrolled monocular videos (e.g., Internet videos). We show our system advances the state of the art in video-based facial performance capture by comparing against alternative methods.
Fuhao Shi, Texas A&M University
Muscle Wu, Microsoft Research Asia
Xin Tong, Microsoft Research Asia
Jinxiang Chai, Texas A&M University
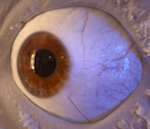
High-Quality Capture of Eyes
We present the first method to capture human eyes in high-quality, including the sclera, cornea and iris, showing fine scale details that make each individual eye unique. We also reconstruct iris deformation during pupil dilation and demonstrate applications of iris animations for visual effects.
Pascal Bérard, ETH Zurich and Disney Research Zurich
Derek Bradley, Disney Research Zurich
Thabo Beeler, Disney Research Zurich
Maurizio Nitti, Disney Research Zurich
Markus Gross, ETH Zurich and Disney Research Zurich

Dynamic Hair Capture Using Spacetime Optimization
We present a dynamic hair capture system for reconstructing realistic hair motions from multiple synchronized video sequences. This is achieved by using a novel hair motion tracking algorithm and formulating the global hair reconstruction as a spacetime optimization problem.
Zexiang Xu, Beihang University
Hsiang-Tao Wu, Microsoft Research Asia
Lvdi Wang, Microsoft Research Asia
Changxi Zheng, Columbia University
Xin Tong, Microsoft Research Asia
Yue Qi, Beijing University of Aeronautics and Astronautics

Capturing Braided Hairstyles
Braided hairstyles exhibit complex intertwining structures which are difficult to reconstruct using state-of-the-art hair capture techniques. We present a data-driven framework to faithfully reconstruct braided hairstyles by leveraging structure information provided by a procedurally created database.
Liwen Hu, University of Southern California
Chongyang Ma, University of Southern California
Linjie Luo, Adobe Research
Li-Yi Wei, The University of Hong Kong
Hao Li, University of Southern California