 English
English 
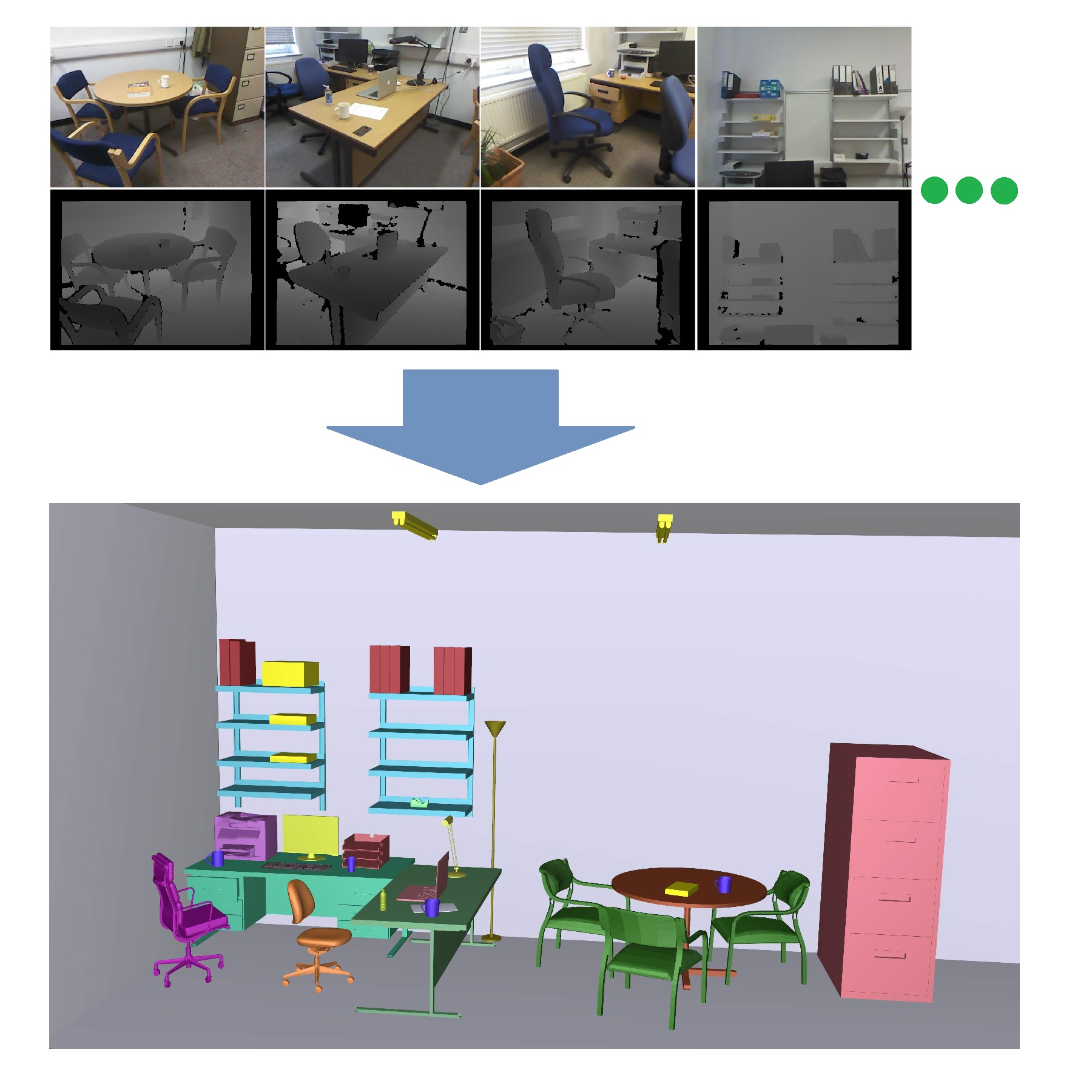
Automatic Semantic Modeling of Indoor Scenes from Low-quality RGB-D Data Using Contextual Information
We present a novel solution to automatic semantic modeling of indoor scenes from a sparse set of low-quality RGB-D images captured by a Microsoft Kinect camera.
Kang Chen, Tsinghua University
Yu-Kun Lai, Cardiff University
Yu-Xin Wu, Tsinghua University
Ralph Martin, Cardiff University
Shi-Min Hu, Tsinghua University
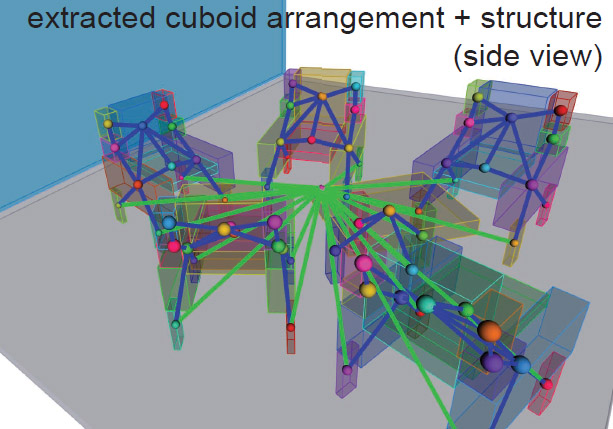
Imagining the Unseen: Stability-based Cuboid Arrangements for Scene Understanding
A physical stability based approach to inferring the actual arrangement of indoor scenes by abstracting the scenes as collections of cuboids and hallucinating geometry in occluded regions, to help understand cluttered indoor scenes.
Tianjia Shao, Zhejiang University
Aron Monszpart, University College London
Youyi Zheng, Yale University
Bongjin Koo, University College London
Weiwei Xu, Hangzhou Normal University
Kun Zhou, Zhejiang University
Niloy Mitra, University College London

Structure Completion for Facade Layouts
We present a method to complete missing structures in facade layouts. Our solution is to break the problem into two components: a statistical model to evaluate layouts and a planning algorithm to generate candidate layouts. This ensures the completed result is consistent with the observation and the layouts in database.
Lubin Fan, Zhejiang University
Przemyslaw Musialski, Vienna University of Technology
Ligang Liu, University of Science and Technology of China
Peter Wonka, King Abdullah University of Science and Technology
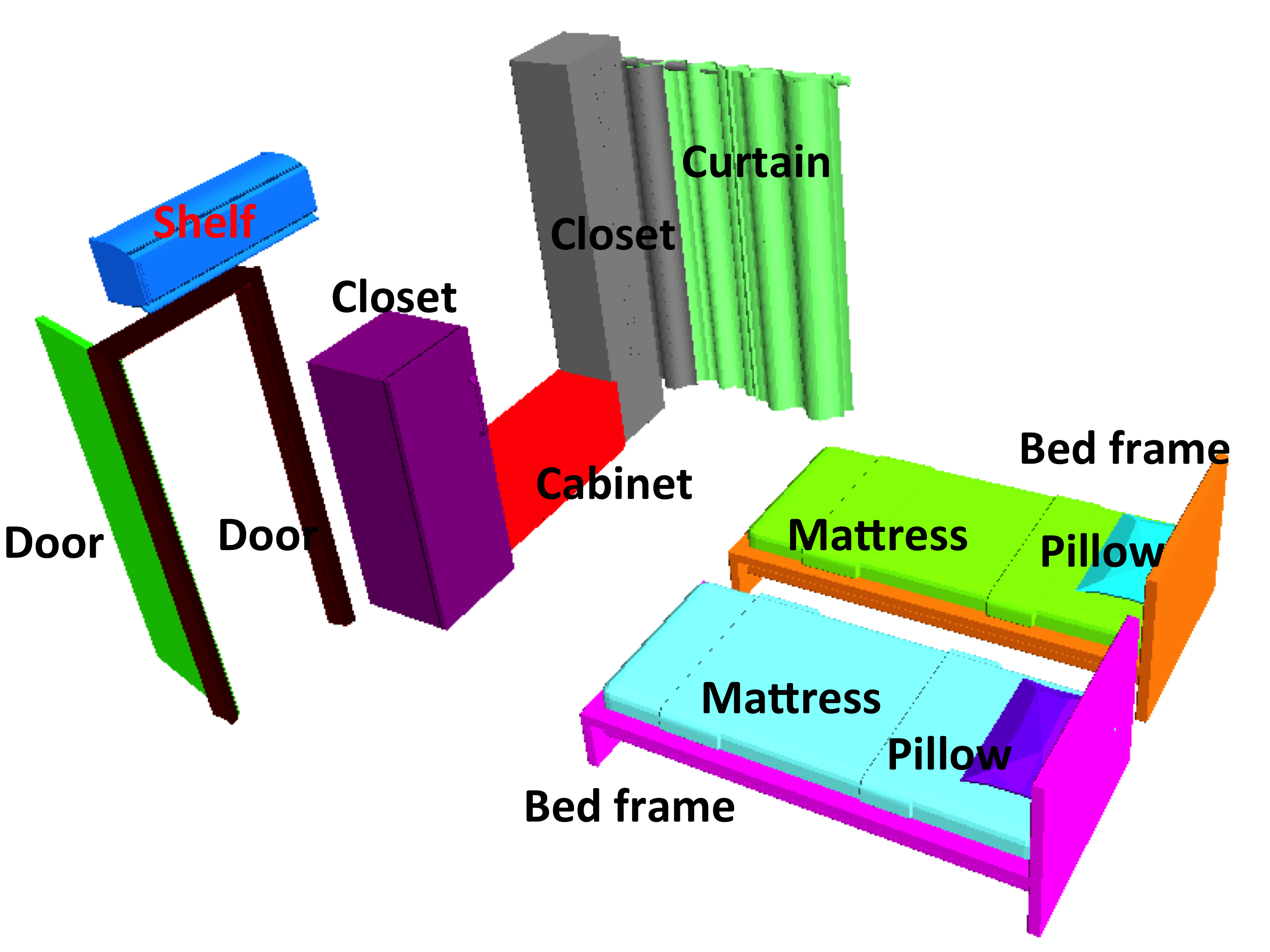
Creating Consistent Scene Graphs Using a Probabilistic Grammar
We develop algorithms that infer consistent segmentations, category labels and functional grouping via parsing with a probabilistic grammar learned from examples. In particular, we explicitly learn and leverage the hierarchical structure of scenes. Our experiments demonstrate that hierarchical analysis infers more accurate object labels than alternative methods.
Tianqiang Liu, Princeton University
Siddhartha Chaudhuri, Princeton University
Vladimir Kim, Stanford University
Qixing Huang, Stanford University
Niloy Mitra, University College London
Thomas Funkhouser, Princeton University
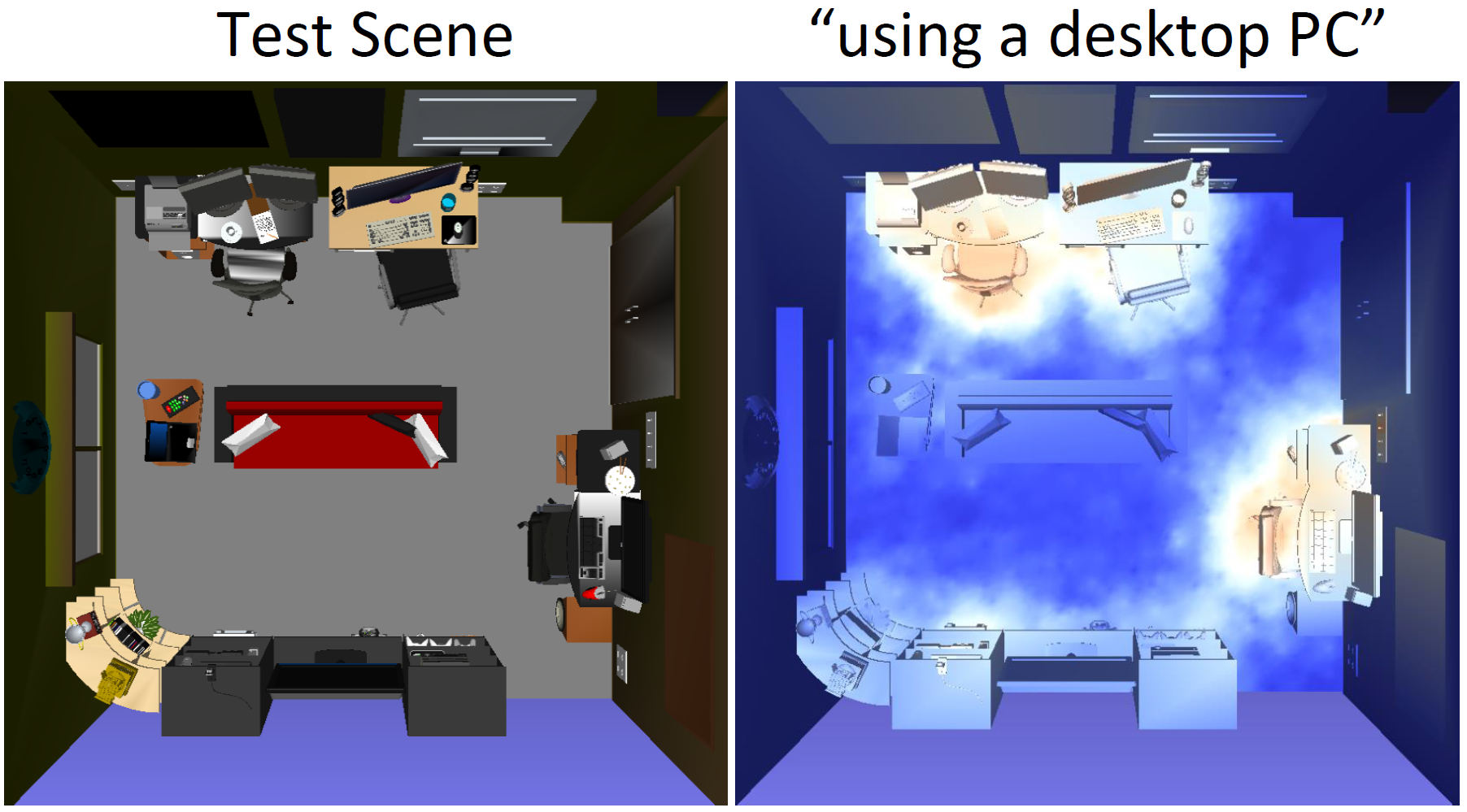
SceneGrok: Inferring Action Maps in 3D Environments
We present a method to predict the likelihood of a given action taking place over all locations in a 3D environment and refer to this representation as an action map over the scene. We demonstrate prediction of action maps in both 3D scans and virtual scenes.
Manolis Savva, Stanford University
Angel Chang, Stanford University
Pat Hanrahan, Stanford University
Matthew Fisher, Stanford University
Matthias Niessner, Stanford University